
Overview
The Deepseek-R1 1.5B Langchain AI Agent (RAG) on NVIDIA Jetson™ delivers a plug-and-play AI runtime purpose-built for Retrieval-Augmented Generation workflows on edge devices. This container integrates the DeepSeek R1 1.5B model (served via Ollama) with LangChain's FastAPI middleware and OpenWebUI, providing a complete, lightweight, GPU-accelerated solution for real-time, offline RAG applications.
Designed for edge AI workflows, it offers an efficient development environment to implement document-grounded Q&A, contextual assistants, and autonomous agents—all running locally on Jetson devices. The prebuilt sample enables developers to quickly build custom RAG pipelines with hardware-optimized performance for intelligent, context-aware applications.

This container enables:
| Feature | Description |
|---|---|
| Offline LLM Inference | DeepSeek R1 1.5B via Ollama (no internet required post-setup) |
| LangChain Middleware | FastAPI orchestration for modular pipelines |
| FAISS Vector Database | Built-in semantic search for efficient RAG |
| Agent Support | Autonomous multi-step task execution |
| Context Management | Prompt memory for smarter conversations |
| Streaming Chat UI | OpenWebUI interface |
| OpenAI-Compatible API | Seamless integration endpoints |
| Customizable Parameters | Modelfile & environment variable configuration |
| RAG Sample | Prebuilt code demonstrating RAG implementation |
Container Demo
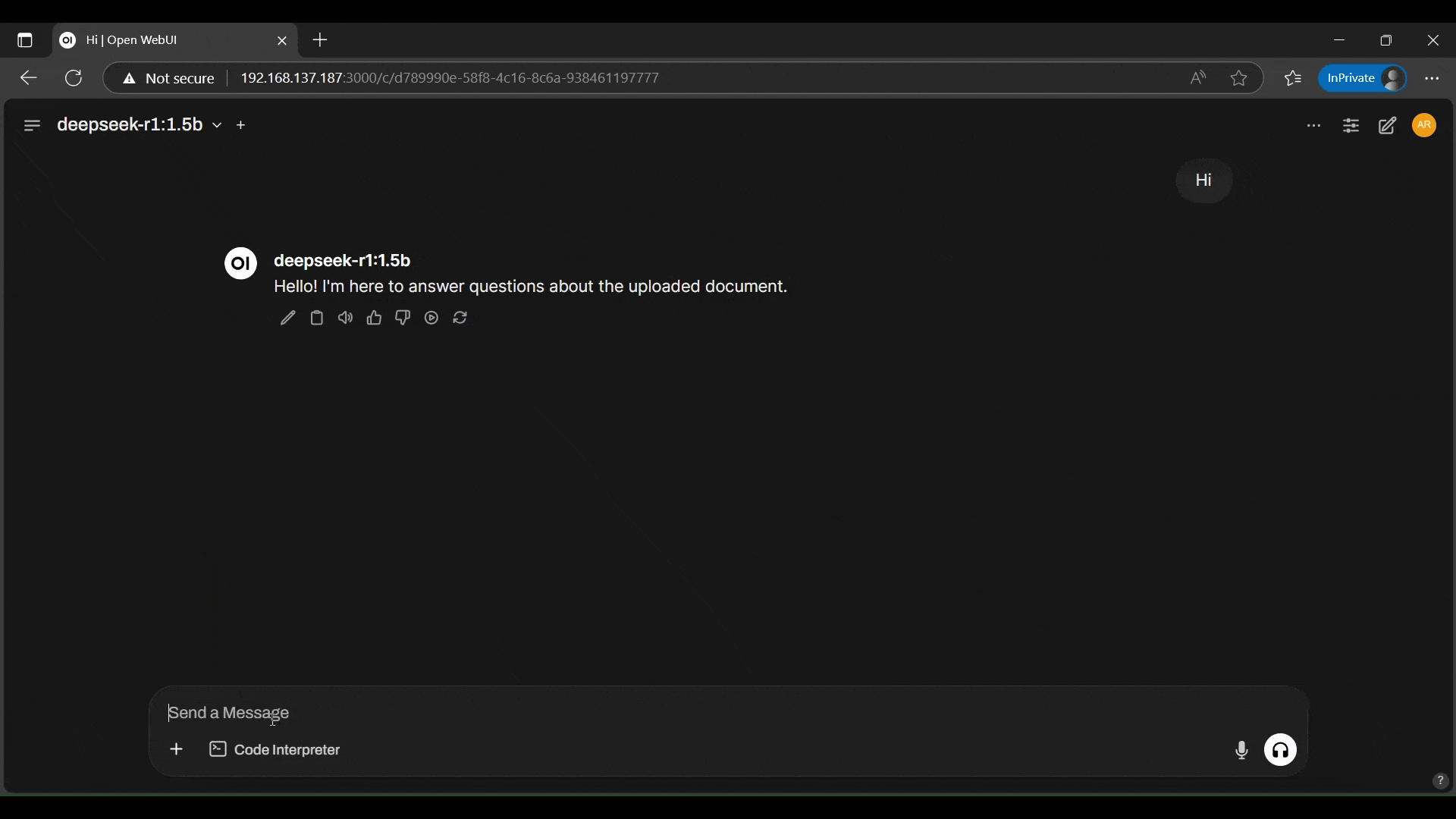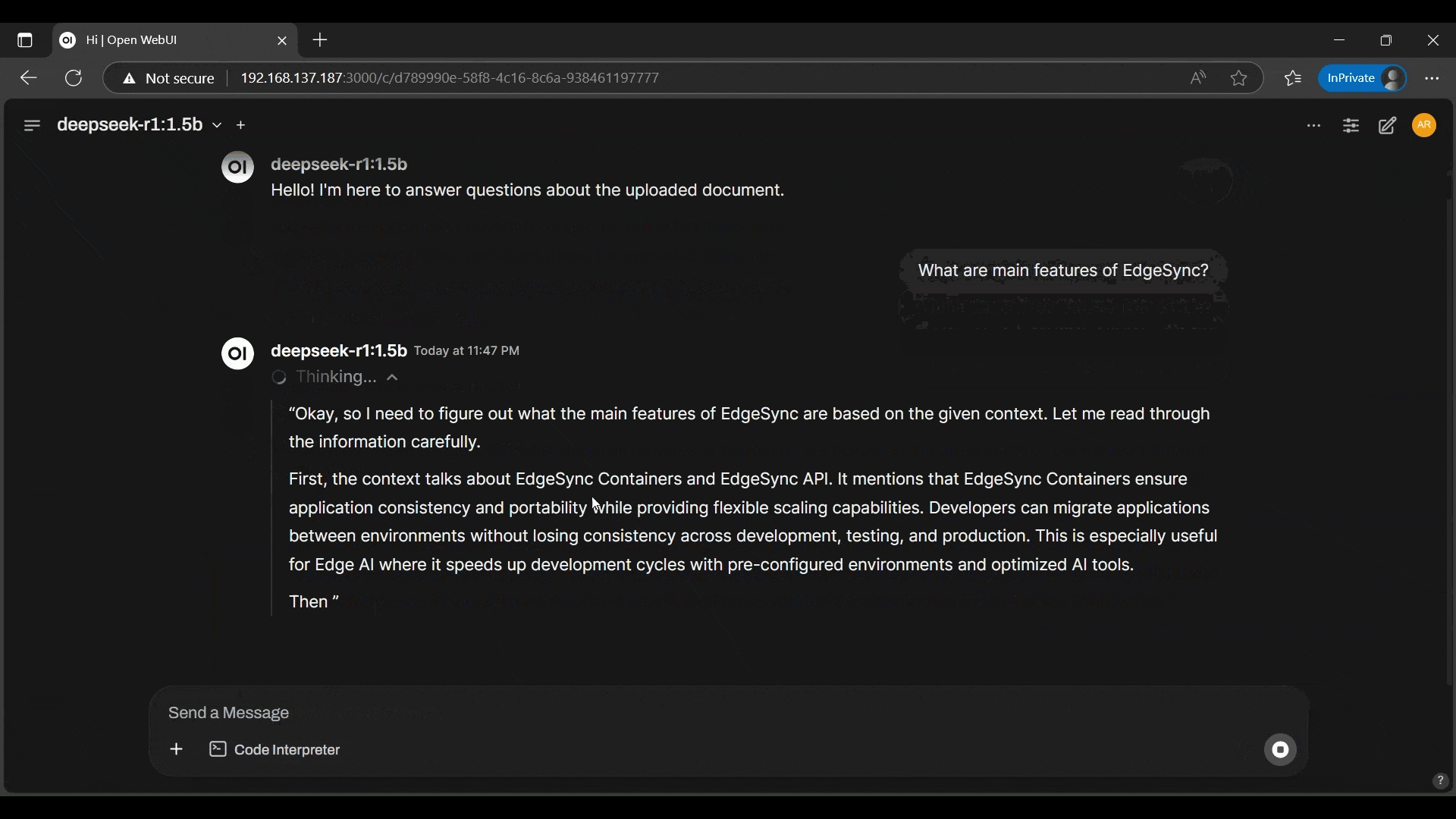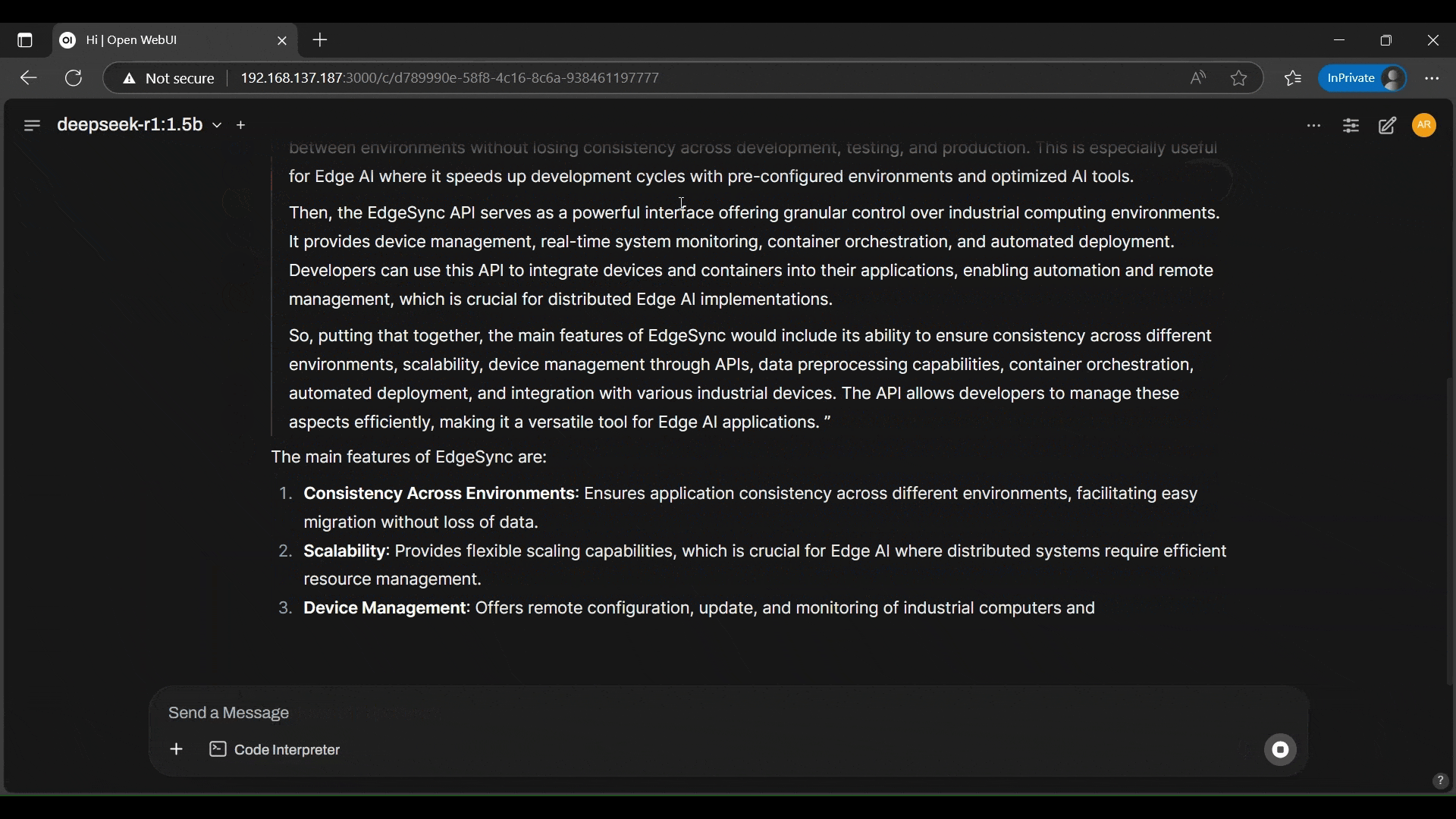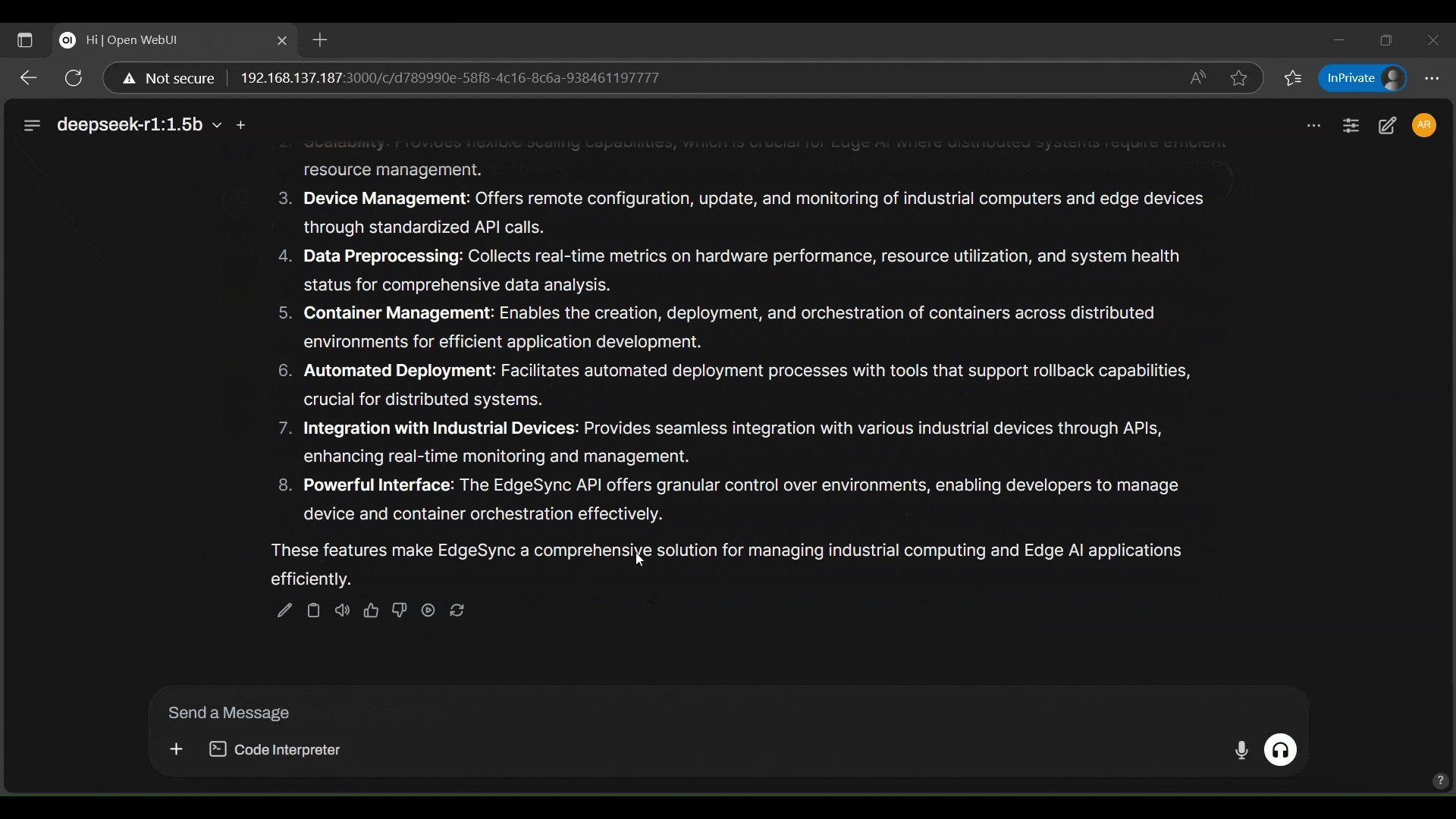
- DeepSeek is answering questions, based on the preloaded PDF file.
Use Cases
| Use Case | Description |
|---|---|
| Legal Document Assistant | Query contracts, case law, or legal memos without cloud exposure |
| Internal SOP Assistant | Smart assistant for Standard Operating Procedures across departments |
| Medical Protocol Access | Offline retrieval from medical guidelines and drug data in low-connectivity zones |
| Compliance & Audit Q&A | Offline LLMs for policy compliance and regulatory alignment summaries |
| Safety Manual Agents | Instant answers from safety manuals to improve protocol adherence |
| Conversational RAG | Extend container capabilities for custom RAG development |
| Tool-Enabled Agents | Intelligent agents with calculator, API, and search tool integration |
Technical Components
| Component | Description |
|---|---|
| LangChain Middleware | Agent logic with memory and modular chains |
| Prebuilt RAG Example | PDF retrieval application for reference/extension |
| Ollama Integration | Lightweight inference engine for quantized models |
| AI Framework Stack | PyTorch, TensorFlow, ONNX Runtime, and TensorRT™ |
| Industrial Vision | Accelerated OpenCV and GStreamer pipelines |
| Edge AI Capabilities | Computer vision, LLMs, and time-series analysis |
| Performance Optimized | Tuned for NVIDIA® Jetson Orin™ NX 8GB |
| RAG/Agent Support | Accelerated development environment for agent workflows |
Host Device Prerequisites
| Item | Specification |
|---|---|
| Compatible Hardware | Advantech devices accelerated by NVIDIA Jetson™—refer to Compatible hardware |
| NVIDIA Jetson™ Version | 5.x |
| Host OS | Ubuntu 20.04 |
| Required Software Packages | Refer to Below |
| Software Installation | NVIDIA Jetson™ Software Package Installation |
Container Environment Overview
Software Components on Container Image
| Component | Version | Description |
|---|---|---|
| CUDA® | 11.4.315 | GPU computing platform |
| cuDNN | 8.6.0 | Deep Neural Network library |
| TensorRT™ | 8.5.2.2 | Inference optimizer and runtime |
| PyTorch | 2.0.0+nv23.02 | Deep learning framework |
| TensorFlow | 2.12.0 | Machine learning framework |
| ONNX Runtime | 1.16.3 | Cross-platform inference engine |
| OpenCV | 4.5.0 | Computer vision library with CUDA® |
| GStreamer | 1.16.2 | Multimedia framework |
| Ollama | 0.5.7 | LLM inference engine |
| LangChain | 0.2.17 | Orchestration layer for memory, RAG, and agent workflows |
| FastAPI | 0.115.12 | API service exposing LangChain interface |
| OpenWebUI | 0.6.5 | Web interface for chat interactions |
| FAISS | 1.8.0.post1 | Vector store for RAG pipelines |
| RAG Code Sample | NA | Sample code that shows RAG capability development |
| Sentence-T5-Base | NA | Pulls sentence-t5-base embedding model from HF |
Quick Start Guide
For container quick start, including the docker-compose file and more, please refer to README.
Supported AI Capabilities
Language Models Recommendation
| Model Family | Parameters | Quantization | Size | Performance |
|---|---|---|---|---|
| DeepSeek R1 | 1.5 B | Q4_K_M | 1.1 GB | ~15-17 tokens/sec |
| DeepSeek R1 | 7 B | Q4_K_M | 4.7 GB | ~5-7 tokens/sec |
| DeepSeek Coder | 1.3 B | Q4_0 | 776 MB | ~20-25 tokens/sec |
| Llama 3.2 | 1 B | Q8_0 | 1.3 GB | ~17-20 tokens/sec |
| Llama 3.2 Instruct | 1 B | Q4_0 | ~0.8 GB | ~17-20 tokens/sec |
| Llama 3.2 | 3 B | Q4_K_M | 2 GB | ~10-12 tokens/sec |
| Llama 2 | 7 B | Q4_0 | 3.8 GB | ~5-7 tokens/sec |
| Tinyllama | 1.1 B | Q4_0 | 637 MB | ~22-27 tokens/sec |
| Qwen 2.5 | 0.5 B | Q4_K_M | 398 MB | ~25-30 tokens/sec |
| Qwen 2.5 | 1.5 B | Q4_K_M | 986 MB | ~15-17 tokens/sec |
| Qwen 2.5 Coder | 0.5 B | Q8_0 | 531 MB | ~25-30 tokens/sec |
| Qwen 2.5 Coder | 1.5 B | Q4_K_M | 986 MB | ~15-17 tokens/sec |
| Qwen | 0.5 B | Q4_0 | 395 MB | ~25-30 tokens/sec |
| Qwen | 1.8 B | Q4_0 | 1.1 GB | ~15-20 tokens/sec |
| Gemma 2 | 2 B | Q4_0 | 1.6 GB | ~10-12 tokens/sec |
| Mistral | 7 B | Q4_0 | 4.1 GB | ~5-7 tokens/sec |
Tuning Tips for Efficient RAG and Agent Workflows:*
- Use asynchronous chains and streaming response handlers to reduce latency in FastAPI endpoints.
- For RAG pipelines, use efficient vector stores (e.g., FAISS with cosine or inner product) and pre-filter data when possible.
- Avoid long chain dependencies; break workflows into smaller composable components.
- Cache prompt templates and tool results when applicable to reduce unnecessary recomputation
- For agent-based flows, limit tool calls per loop to avoid runaway execution or high memory usage.
- Log intermediate steps (using LangChain’s callbacks) for better debugging and observability
- Use models with ≥3B parameters (e.g., Llama 3.2 3B or larger) for agent development to ensure better reasoning depth and tool usage reliability.
- Use FAISS or Chroma with pre-computed embeddings for faster retrieval
- Apply score thresholding in retriever config to filter irrelevant documents
- Keep persistent vector DB (e.g., FAISS saved index) to avoid re-indexing on container restart
- Use appropriate (size/precision) embedding models as per the suitability of the use case.
Copyright © Advantech Corporation. All rights reserved.