.webp)
Overview
Edge RAG AI Agent on AMD Ryzen™ with ROCm™
Short summary: Enterprise-grade LLM inference with Retrieval-Augmented Generation (RAG) for building intelligent AI agents on AMD Ryzen systems, featuring offline capability, document QA, and hardware acceleration.
About Advantech Container Catalog (ACC)
Advantech Container Catalog is a comprehensive collection of ready-to-use, containerized software packages designed to accelerate the development and deployment of Edge AI applications. By offering pre-integrated solutions optimized for embedded hardware, it simplifies the challenges often faced with software and hardware compatibility, especially in GPU/NPU-accelerated environments.
| Feature / Benefit | Description |
|---|---|
| Accelerated Edge AI Development | Ready-to-use containerized solutions for faster prototyping and deployment |
| Hardware Compatible | Reduces hardware and package incompatibility issues |
| GPU/NPU Access Ready | Supports passthrough for efficient hardware acceleration |
| Model Conversion & Optimization | Built-in model conversion and quantization recommendations |
| Optimized for CV & LLM Applications | Optimized stacks for vision and language workloads |
Container Overview
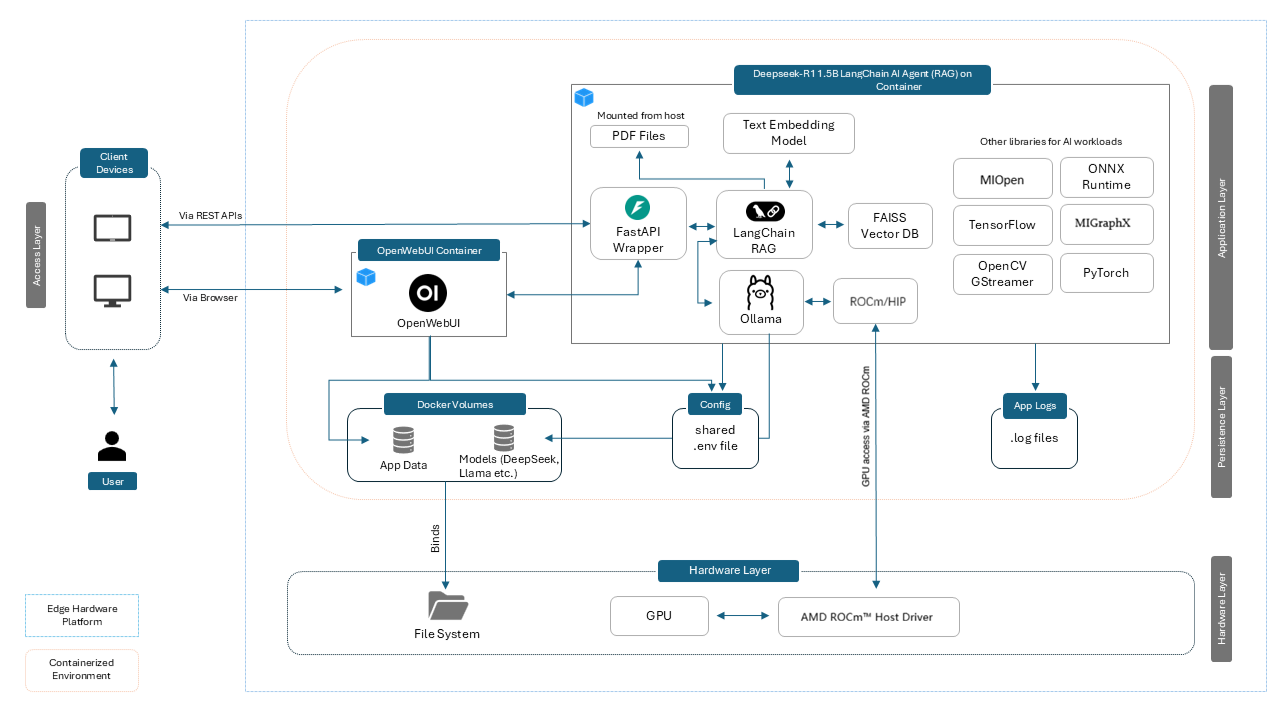
This container delivers a modular, high-performance AI agent solution tailored for AMD Ryzen ROCm devices. It combines Ollama for efficient on-device LLM inference, LangChain for orchestration and tool integration, FastAPI middleware for API exposure, and OpenWebUI for an intuitive interface. The architecture supports Retrieval-Augmented Generation (RAG), multi-turn conversations, custom tool integration, and offline-first operations—ideal for building intelligent, context-aware agents that process PDF documents and respond with retrieved information.
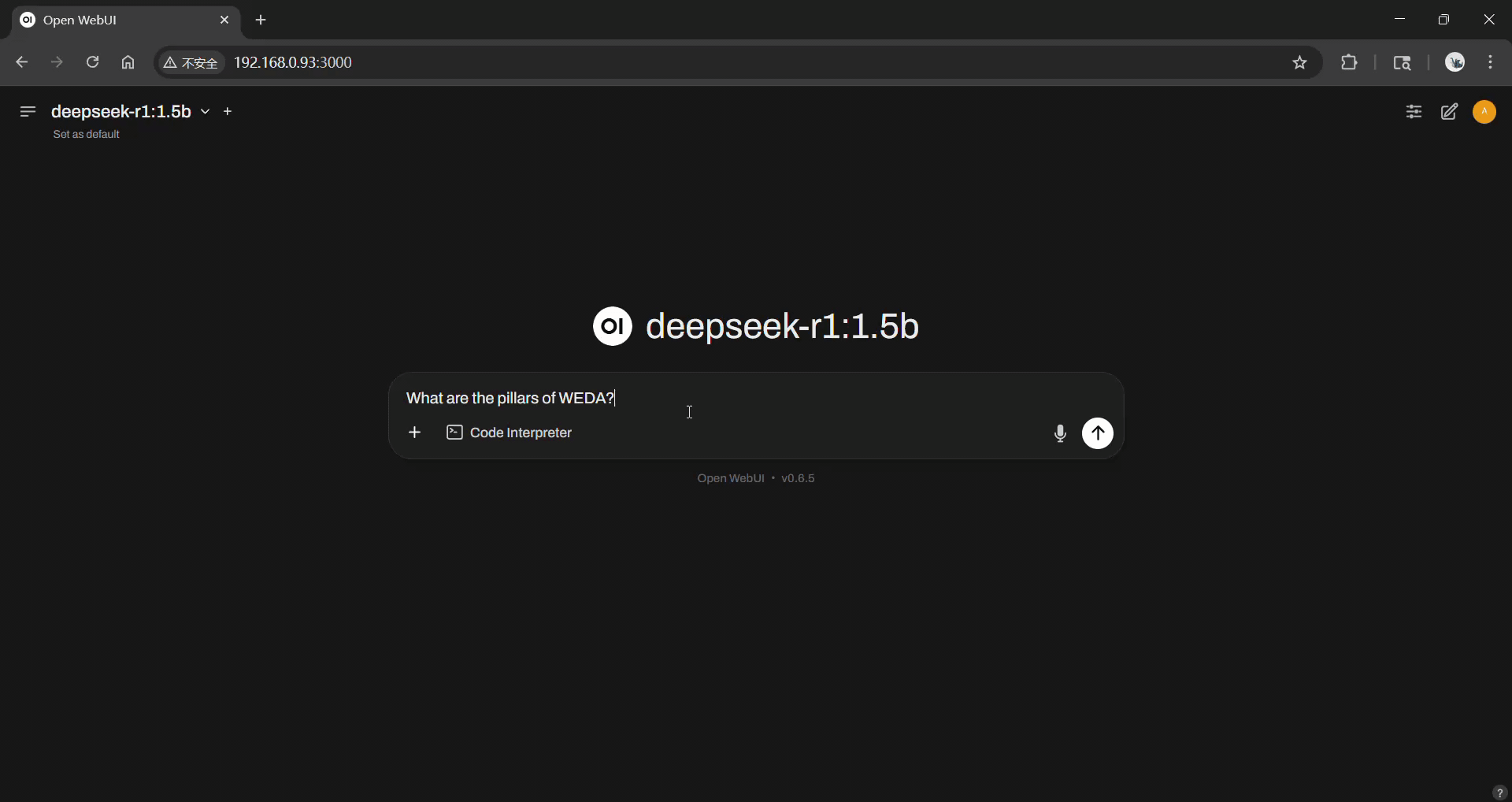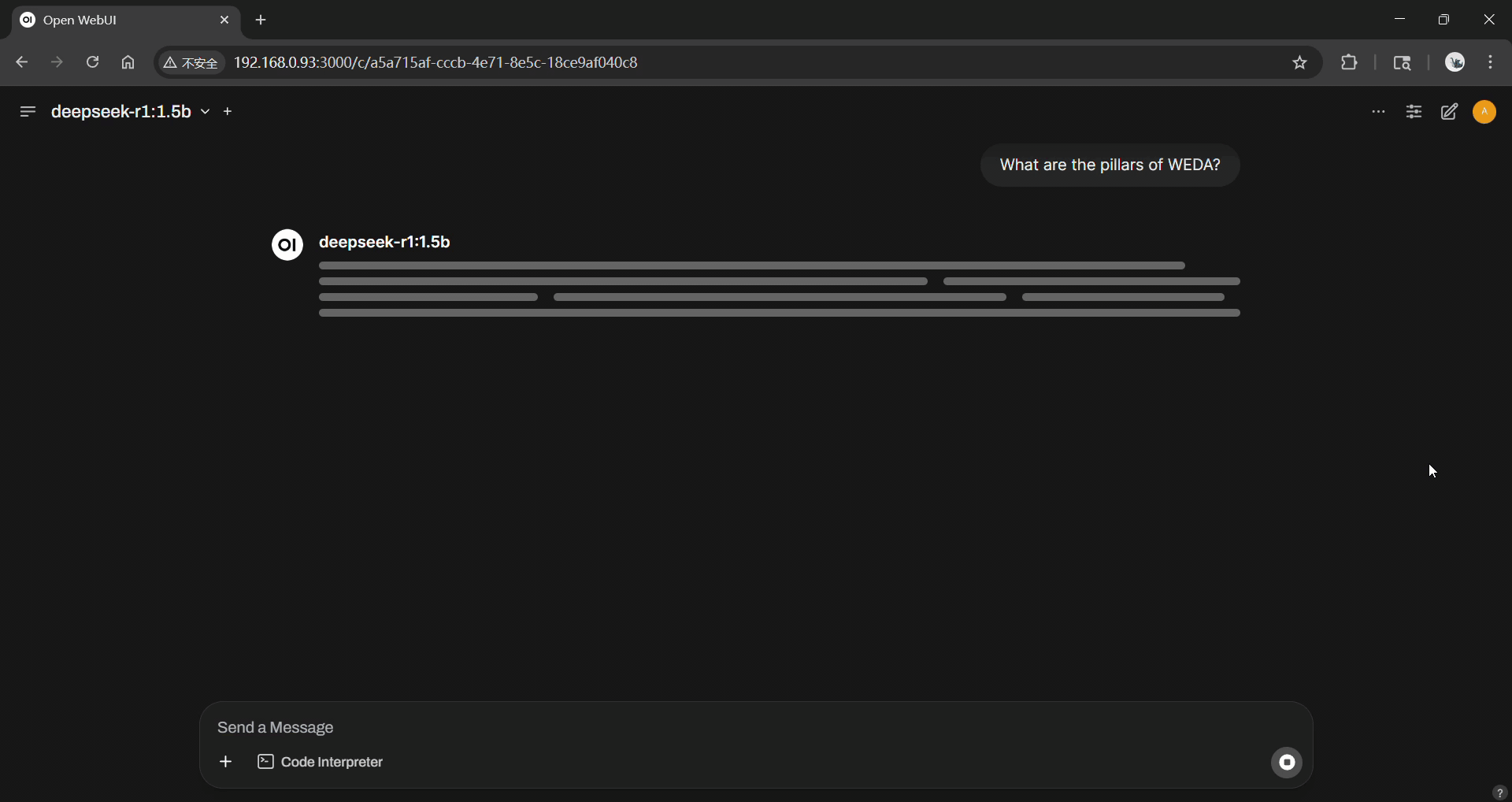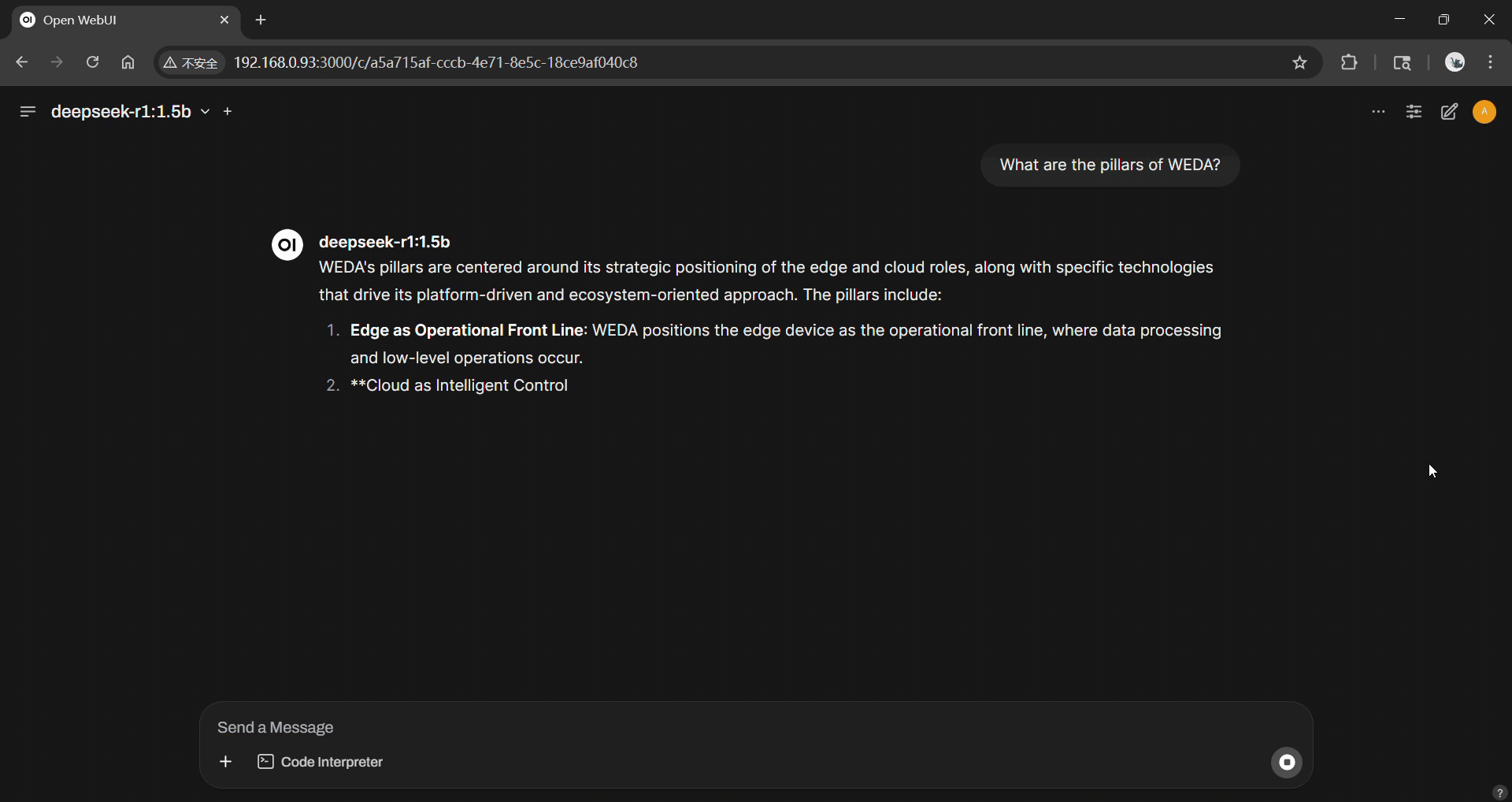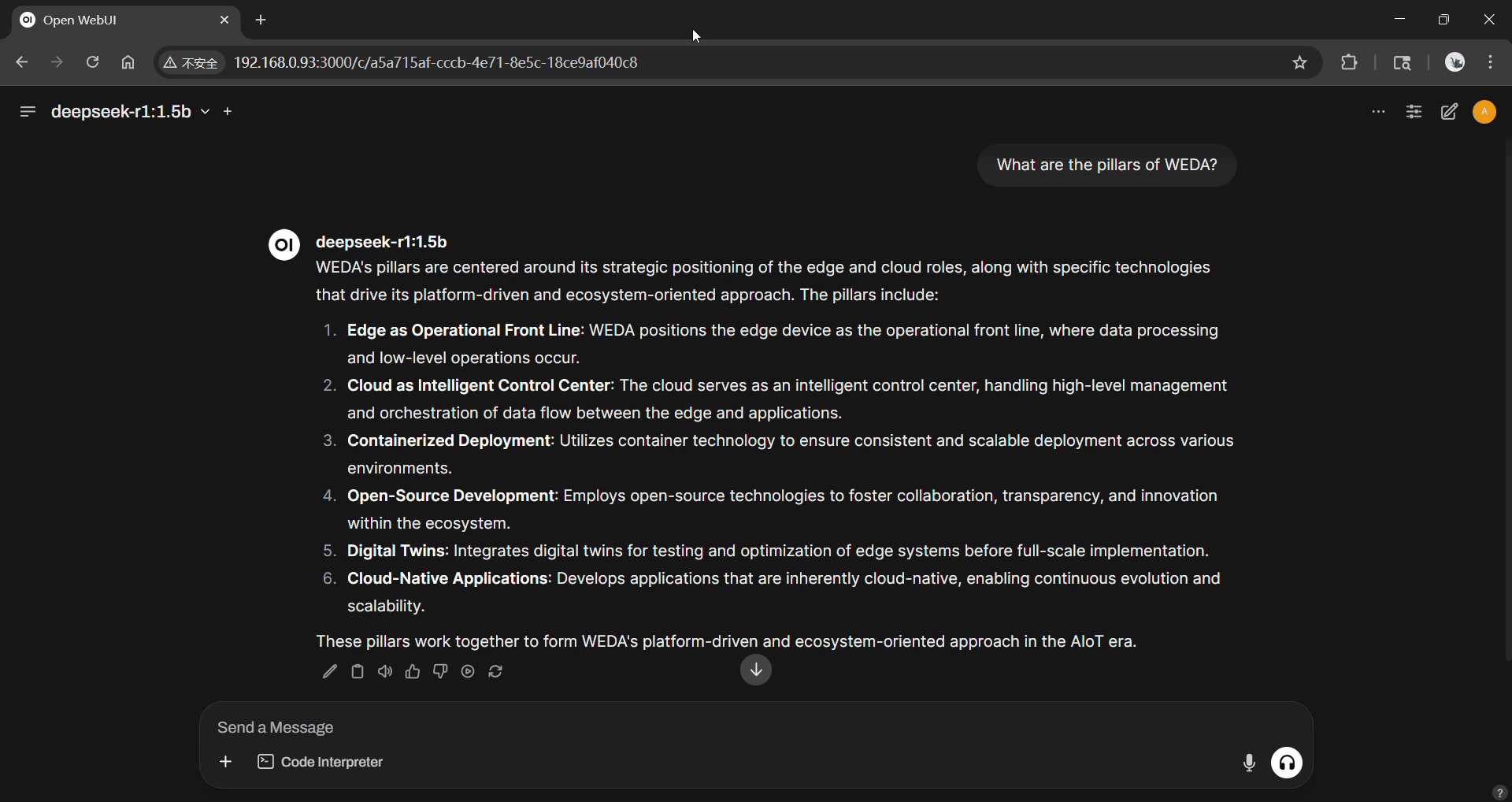
Demo
RAG Query Demo:
Use Case
- Legal document assistants with offline data privacy
- Internal SOP (Standard Operating Procedure) assistants
- Medical protocol access for healthcare professionals
- Compliance and audit Q&A systems
- Safety manual conversational agents
- Technician support and troubleshooting bots
- Industrial edge controllers using AI agents
- Retrieval-augmented generation for domain-specific QA
- Tool-enabled intelligent agents with reasoning capabilities
- Corporate knowledge base chatbots
Key Features
- DeepSeek-R1 1.5B Inference: Lightweight, efficient on-device LLM with minimal memory footprint
- LangChain Integration: Modular framework for building complex AI workflows and agents
- RAG Capability: Retrieval-Augmented Generation for document-based question answering
- FastAPI Middleware: RESTful APIs for seamless integration with frontends and services
- OpenWebUI Interface: User-friendly chat interface for real-time LLM interaction
- Offline Operation: Fully functional after initial setup; no internet required
- Tool Integration: Support for external tools, calculators, and search capabilities
- Conversational Memory: Multi-turn conversations with context retention
- Hardware Acceleration: Optimized for AMD Ryzen ROCm GPUs (Radeon 780M)
- Model Customization: Easy model switching and fine-tuning via Ollama
- Streaming Support: Real-time response streaming for interactive UX
Host Device Prerequisites
| Item | Specification |
|---|---|
| Compatible Hardware | AMD Ryzen systems with ROCm support (e.g., Ryzen 7 PRO 8845HS with Radeon 780M) |
| GPU | AMD Radeon 780M or compatible ROCm-supported GPU |
| Memory | 4GB minimum, 8GB+ recommended for optimal performance |
| Host OS | Linux (Ubuntu 22.04+ recommended) |
| Required Packages | Docker, Docker Compose, ROCm Runtime |
Required Software Packages on Host Device
| Component | Version | Description |
|---|---|---|
| Docker | 28.1.1+ | Container runtime platform |
| Docker Compose | 2.39.1+ | Multi-container orchestration |
| ROCm Runtime | Latest | AMD GPU acceleration framework |
| ROCm Driver | Latest | GPU driver for hardware support |
Container Environment Overview
Software Components in the Image
| Component | Version | Description |
|---|---|---|
| Ollama | 0.17.5 | LLM inference engine |
| LangChain | 0.2.17 | LLM orchestration and agent framework |
| FastAPI | 0.115.12 | REST API framework for middleware |
| OpenWebUI | 0.6.5 | Web-based chat interface |
| DeepSeek-R1 | 1.5B | Lightweight language model |
| ONNX Runtime | 1.16.3 | Cross-platform inference engine |
| GStreamer | 1.24.2 | Multimedia framework |
| FAISS | 1.8.0+ | Vector store for RAG and similarity search |
| Sentence-T5-Base | Latest | Embedding model from HuggingFace |
Container Quick Start Guide
For installation, setup, build scripts, and detailed usage instructions, please refer to the Advantech Containers Github Repository in the repository.
Supported AI Capabilities
Model Information
| Item | Description |
|---|---|
| Primary Model | DeepSeek-R1 1.5B |
| Model Architecture | Qwen2-based |
| Quantization | Q4_K_M |
| Ollama Command | ollama pull deepseek-r1:1.5b |
| Parameters | ~1.78 Billion |
| Model Size | ~1.1 GB |
| Context Window | 2048 tokens (configurable) |
Model Customization Options
Users can switch models within the .env file:
deepseek-r1:1.5b(default)qwen2.5:0.5b(ultra-lightweight)qwen2.5:1.5b(similar size)qwen3:1.7b(larger context)
Document Types
| Attribute | Details |
|---|---|
| Supported Format | PDF (text-based) |
| Maximum File Size | 170 MB (~4,300 pages) |
| Unsupported | Scanned/image PDFs, encrypted files, Word/CSV documents |
| Multi-Document | Multiple PDFs supported simultaneously |
| Language | English language documents |
RAG & Retrieval Features
| Feature | Support |
|---|---|
| Vector Store | FAISS with pre-computed embeddings |
| Embedding Model | Sentence-T5-Base |
| Similarity Search | Cosine and inner product similarity |
| Score Thresholding | Configurable via SCORE_THRESHOLD environment variable |
| Persistent Storage | FAISS saved index for container restarts |
| Chunk Processing | Automatic document chunking and splitting |
AI Agent Capabilities
| Capability | Description |
|---|---|
| Tool Integration | Custom tools and function calling |
| Memory Types | Buffer, summary, and vector-based recall |
| Streaming | Real-time response streaming |
| Async Support | Non-blocking pipeline execution |
| Conversation Chains | Multi-turn dialogue with context |
| Reasoning | Step-by-step reasoning with tool usage |
Hardware Acceleration Support
| Accelerator | Support Level | Compatible Libraries | Notes |
|---|---|---|---|
| AMD ROCm GPU | Full | Ollama, PyTorch, ONNX Runtime | Primary acceleration target (Radeon 780M) |
| CPU Fallback | Full | LangChain, FastAPI, FAISS | Configurable via OLLAMA_LLM_LIBRARY |
| Quantized Models | Full | Ollama, LLama.cpp | Q4_K_M quantization standard |
Architecture
Component Stack
- Ollama: Local LLM inference engine with model management
- DeepSeek-R1 1.5B: Efficient language model for reasoning and generation
- LangChain: Framework for chains, agents, and workflows
- FAISS: Vector database for RAG semantic search
- FastAPI: REST middleware between OpenWebUI and LangChain
- OpenWebUI: User-facing chat interface
Data Flow
Document Upload → PDF Parsing → Chunking → Embedding → Vector Store → Query Processing → Retrieval → LLM Response → Streaming UI
Best Practices for Document Preparation
- Ensure documents are topically consistent and logically structured
- Remove irrelevant sections (watermarks, repeated headers)
- Prefer clean metadata and minimal formatting clutter
- Avoid heavily stylized layouts (multi-column text, embedded visuals)
- Don't mix multiple unrelated domains in the same document set
- Use focused, document-specific prompts (e.g., "What are the features of X?")
- Reference document structure explicitly in queries
- Restart services after adding/removing/changing PDF files
- Increase swap size if RAM is less than 8GB
Copyright © Advantech Corporation. All rights reserved.