
Overview
eIQ GenAI Flow 2.0 on NXP i.MX95
Overview
The eIQ GenAI Flow docker container by Advantech WEDA is a modular and scalable pipeline to create exciting AI-powered experiences on edge devices. The Flow provides a one stop shop to build production-grade, generative AI using the i.MX 95’s powerful NPU to accelerate LLM inference. The docker container and python API architecture is the ultimate tool for AI practitioners to bring their ideas to NXP’s edge computing ecosystem.
Block Diagram
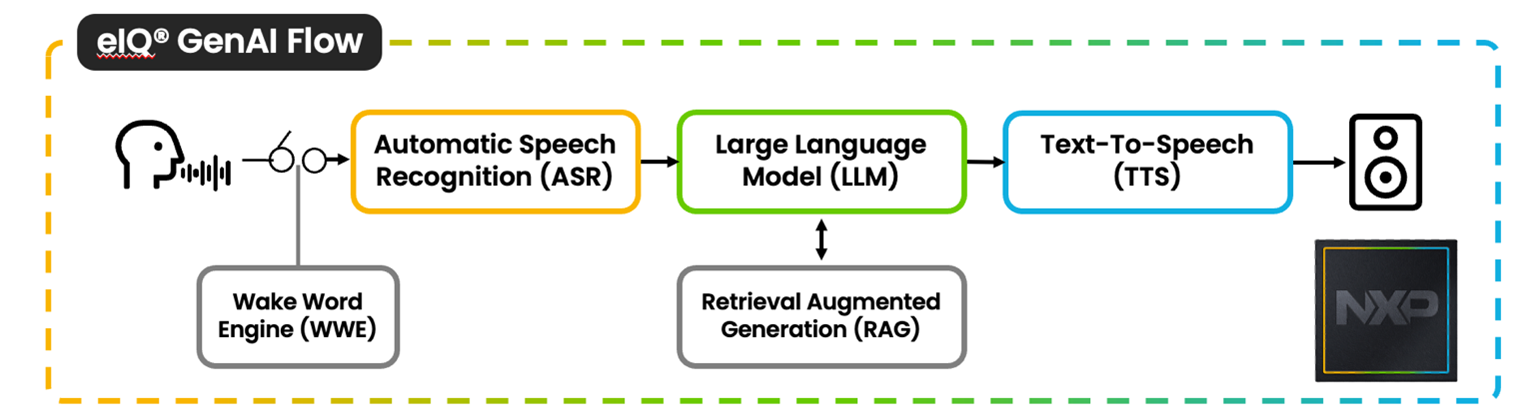
Advantech WEDA container successfully containerizes NXP eIQ GenAI Flow 2.0, making deployment and future deployment easier with Advantech WEDA. More details regarding NXP eIQ GenAI Flow V2.0
Key Features
| Feature | Description |
|---|---|
| eIQ® GenAI Flow 2.0 | Integrates multiple AI technologies to create a seamless HMI experience. |
| Edge AI Capabilities | Optimized support for LLM and ASR leveraging NXP NPU acceleration. |
| Hardware Acceleration | Direct passthrough access to NPU hardware for high-performance, low-latency, and low-power inference. |
| Preconfigured Environment | Bundles drivers, toolchains, and AI libraries to eliminate setup time. |
| Rapid Prototyping & Deployment | Streamlines testing AI models and validating PoCs without rebuilding from scratch. |
Value Proposition
Customers can kickstart GenAI development on low-power NXP i.mx95 platform with full end-to-end Gen AI workflow, fully containerized with WEDA, including ASR(Automatic Speech Recognition), LLM, RAG(Retrieval-Augumented Generation), and TTS (Text-to-speech). Plus, containerized GenAI workflow can further be deployed massively through WEDA API, enabling not only 1st edge device development but also scaling & managing Edge AI applications to edge devices.
• What are the Key takeaways?
- Running end-to-end GenAI workflow even on Lower power platform
- Enable deployment via containerized environment and handle edge AI development lifecycle, including AI model & containerized edge Application mass deployment, device and data management through WEDA.
Hardware Specifications
| Component | Specification |
|---|---|
| Target Hardware | Advantech AOM-5521 |
| SoC | NXP i.MX95 |
| GPU | Arm® Mali™ G310 |
| NPU | eIQ neutron N3-1034S |
| Memory | 8 GB LPDDR5 |
Operating System
| Environment | Operating System |
|---|---|
| Device Host | Yocto 5.2 Walnascar |
| Container | Ubuntu:24.04 |
| Base Container | NXP-iMX95-Neutron-Passthrough Container |
Software Components
| Component | Version | Description |
|---|---|---|
| eIQ GenAI Flow | 2.0 | |
| Python | 3.13 | Python runtime for building applications |
| ONNX Runtime | 1.22.0 from NXP BSP v6.12.20 | Inference runtime |
Supported AI Capabilities
ASR Models
| Model | Format | Note |
|---|---|---|
| moonshine-tiny | .onnx | Provide By NXP eIQ GenAI Flow |
| moonshine-base | .onnx | Provide By NXP eIQ GenAI Flow |
| whisper-small.en | .onnx | Provide By NXP eIQ GenAI Flow |
LLM Models
| Model | Format | Note |
|---|---|---|
| danube-500M-q4 | .onnx | Provide By NXP eIQ GenAI Flow |
| danube-500M-q8 | .onnx | Provide By NXP eIQ GenAI Flow |
TTS Models
| Model | Format | Note |
|---|---|---|
| vits-english | .onnx | Provide By NXP eIQ GenAI Flow |
- The models provide by NXP eIQ GenAI Flow is encrypted .
Hardware Acceleration Support
| Accelerator | Support Level | Compatible Libraries |
|---|---|---|
| NPU | INT8 (primary), INT4 | NXP eIQ GenAI Flow |
Precision Support
| Precision | Support Level | Notes |
|---|---|---|
| INT8 | NPU,CPU | Primary mode for NPU acceleration, best performance-per-watt |
Repository Structure
eIQ-GenAI-Flow2.0-Container-on-NXP-i.mx95/
├── README.md # Overview and quick start steps
├── run.sh # Script to launch the container
└── docker-compose.yml # Configuration file of docker compose
Quick Start Guide
Prerequisites
- Please ensure docker & docker compose are available and accessible on device host OS
- Since default eMMC boot provides only 16 GB storage which is in-sufficient to run/build the container image, it is required to boot the Host OS using a 32 GB (minimum) SD card.
For container quick start, including the docker-compose file and more, please refer to Advantech Container Github Repository
Best Practices
Precision Selection
- Prefer INT8 for NPU acceleration: The i.MX95 NPU is optimized for quantized INT8 models. Always convert to INT8 using post-training quantization or quantization-aware training for maximum performance and efficiency.
Known Limitations
-
Minimum storage Storage required for running Docker containers is 32 GB
-
NPU passthrough Neutron EP error sometimes, reboot the development board may solve this problem.
Neutron: NEUTRON_IOCTL_BUFFER_CREATE failed!: Cannot allocate memory
Copyright © 2026 Advantech Corporation. All rights reserved.