
Overview
GPU Accelerated Deepseek Langchain
About Advantech Container Catalog
Advantech Container Catalog is a comprehensive collection of ready-to-use, containerized software packages designed to accelerate the development and deployment of Edge AI applications. By offering pre-integrated solutions optimized for embedded hardware, it simplifies the challenges often faced with software and hardware compatibility, especially in GPU/NPU-accelerated environments.
Key benefits of the Container Catalog include:
| Feature / Benefit | Description |
|---|---|
| Accelerated Edge AI Development | Ready-to-use containerized solutions for fast prototyping and deployment |
| GPU/NPU Access Ready | Supports passthrough for efficient hardware acceleration |
| Model Conversion & Optimization | Built-in AI model quantization and format conversion support |
| Optimized for CV & LLM Applications | Pre-optimized containers for computer vision and large language models |
| Scalable Device Management | Supports large-scale IoT deployments via EdgeSync, Kubernetes, etc. |
Container Overview
GPU Accelerated Deepseek Langchain Edge AI-enabled container offers end-to-end integration environment required for starting LLM application on GPU accelerated embedded devices, such as Advantech EPC-R7300, and more. This stack uses Ollama with DeepSeek R1 1.5B Model to serve LLM inference, a FastAPI-based Langchain service for middleware logic, and OpenWebUI as the user interface. It could be used to enable tool-augmented reasoning, conversational memory, custom LLM workflows and build Agents. It also offers full hardware acceleration.
Key Features
| Feature | Description |
|---|---|
| Integrated OpenWebUI | Clean, user-friendly frontend for LLM chat interface |
| DeepSeek R1 1.5B Inference | Efficient on-device LLM via Ollama; minimal memory, high performance |
| Model Customization | Create or fine-tune models using ollama create |
| REST API Access | Simple local HTTP API for model interaction |
| Flexible Parameters | Adjust inference with temperature, top_k, repeat_penalty, etc. |
| Modelfile Customization | Configure model behavior with Docker-like Modelfile syntax |
| Prompt Templates | Supports formats like chatml, llama, and more |
| LangChain Integration | Multi-turn memory with ConversationChain support |
| FastAPI Middleware | Lightweight interface between OpenWebUI and LangChain |
| Offline Capability | Fully offline after container image setup; no internet required |
Container Demo
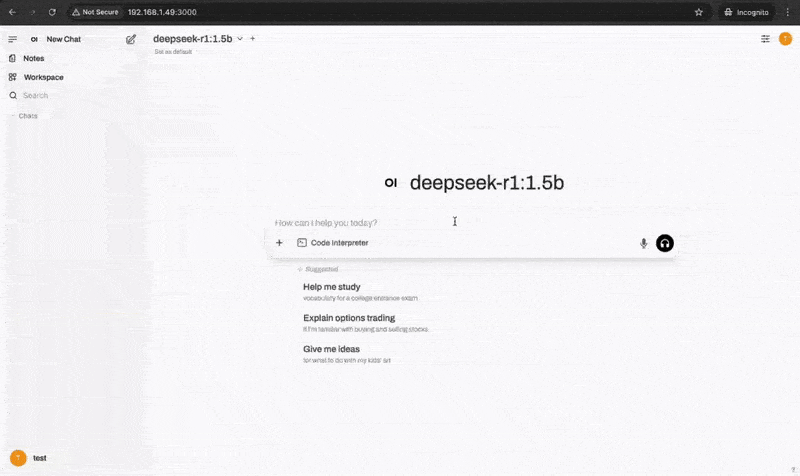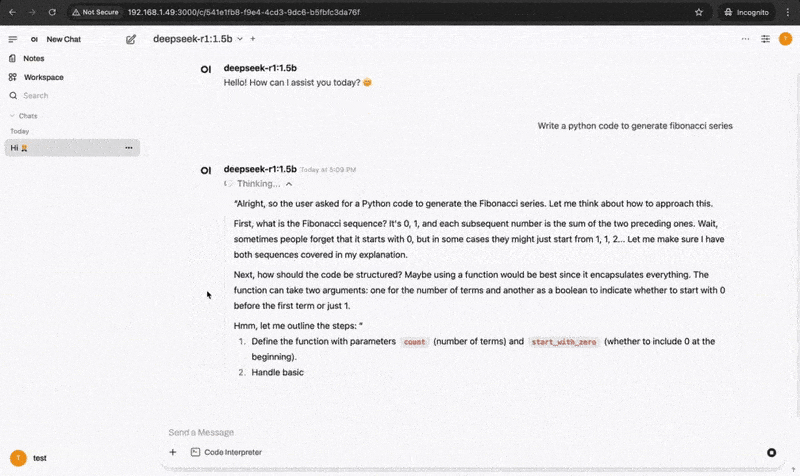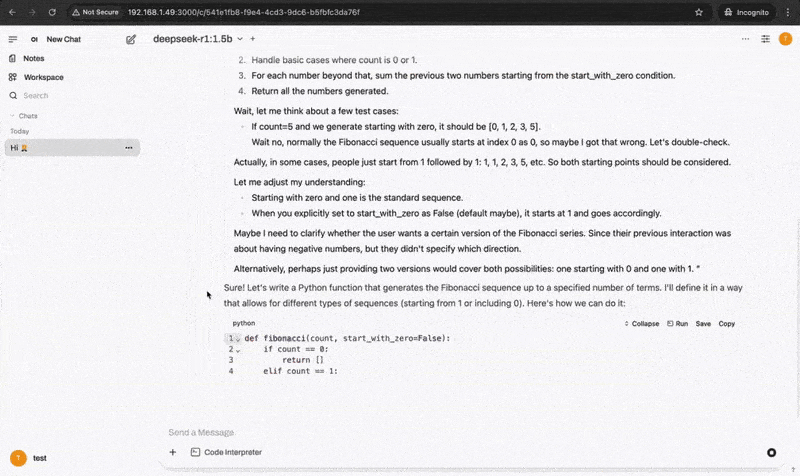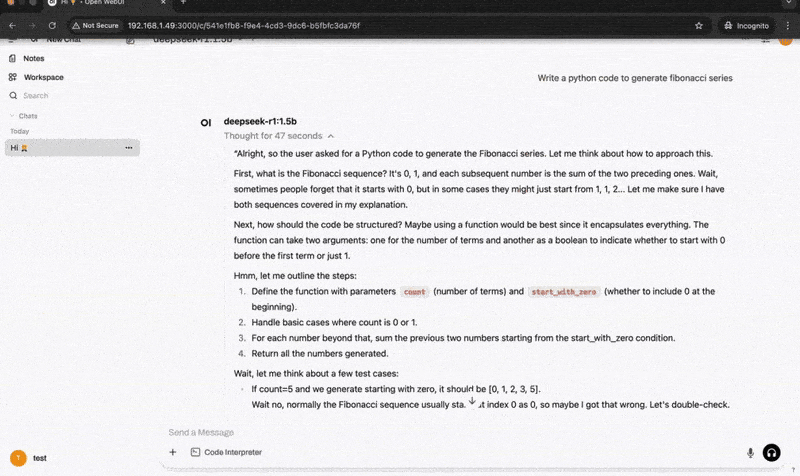
Inference Flow
User → OpenWebUI → FastAPI → LangChain → Ollama → DeepSeek R1 1.5B
Host Device Prerequisites
| Item | Specification |
|---|---|
| Compatible Hardware | Advantech devices accelerated by GPUs - refer to Compatible hardware |
| Host OS | Ubuntu 20.04 |
| Required Software packages | refer to Advantech EdgeSync Container Repository for details |
| Software Installation | Software Package Installation |
Container Environment Overview
Software Components on Container Image
Refer to Advantech EdgeSync Container Repository for details
The following software components/packages are provided further inside this container image & host (via build script), optimized for LLM application:
| Component | Version | Description |
|---|---|---|
| Ollama | 0.5.7 | LLM Backend, installed on Host for better performance |
| LangChain | 0.2.17 | Installed via PIP, framework to build LLM applications |
| FastAPI | 0.115.12 | Installed via PIP, develop OpenAI compatible APIs for serving LangChain |
| OpenWebUI | Latest | Provided via seprate OpenWebUI container for UI |
| DeepSeek R1 1.5B | N/A | Pulled on Host via build script |
Model Information
This image uses DeepSeek R1-1.5B for inferencing, here are the details about the model used:
| Item | Description |
|---|---|
| Model source | Ollama Model (deepseek-r1:1.5b) |
| Model architecture | Qwen2 |
| Model quantization | Q4_K_M |
| Ollama command | ollama pull deepseek-r1:1.5b |
| Number of Parameters | ~1.78 B |
| Model size | ~1.1 GB |
| Default context size (governed by Ollama in this image) | 2048 |
LangChain - LLM Application Development
This image provides an example LangChain service which is served using FastAPI (integrated with OpenWebUI) for easy & quick application development on top of DeepSeek R1 1.5B. The app.py inside container provides sample application that utilizes langchain to do inferences on DeepSeek R1 1.5B via Ollama. Instead of inferencing LLM directly and to do everything at once, LangChain allows to:
Define a 'Chain' of actions
Create a sequence of actions that the LLM will execute. Each action might be a different task, like summarizing text, translating content, or answering questions based on a specific source of information.
Connect different tools
LangChain can hook into various external tools, like:
- LLMs: To generate text, analyze, translate, etc.
- Data Sources: To load information from text files, databases, or APIs.
- Other Utilities : Like web search or even math tools
Manage the flow of information
LangChain acts as the orchestrator, ensuring that the output from one action becomes the input for the next action in the chain. This flow allows for complex operations that are beyond what a single LLM call could achieve.
Quick Start Guide
For container quick start, including docker-compose file, and more, please refer to GPU Accelerated Deepseek Langchain Container Repository
Possible Usecases
Leverage the container image to build interesting use cases like:
| Use Case | Description |
|---|---|
| Predictive Maintenance Chatbots | Integrate with edge telemetry or logs to summarize anomalies, explain error codes, or recommend corrective actions using historical context |
| Compliance and Audit Q&A | Run offline LLMs trained on local policy or compliance data to assist with audits or generate summaries — keeping data on-prem |
| Safety Manual Conversational Agents | Deploy LLMs to provide instant answers from on-site safety manuals or procedures, reducing downtime and improving adherence |
| Technician Support Bots | Field engineers can interact with bots to troubleshoot equipment using repair logs, parts catalogs, and service manuals |
| Smart Edge Controllers | LLMs translate human intent (e.g., “reduce line 2 speed by 10%”) into control commands for industrial PLCs or middleware |
| Conversational Retrieval (RAG) | Integrate with vector databases (e.g., FAISS, ChromaDB) to retrieve context from local docs for Q&A over your custom data |
| Tool-Enabled Agents | Intelligent agents can use tools like calculators, APIs, or search — with LangChain managing the logic and LLM interface |
| Factory Incident Reporting | Ingest logs or voice input → extract incident type → summarize → trigger automated alerts or next steps |
Known Limitations
- Execution Time: Model when inferenced for the first time via OpenWebUI takes longer time (within 10 seconds) as the model gets loaded into the GPU
- RAM Utilization: RAM utilizations for running this container image occupies approximately <=5 GB RAM when running on NVIDIA Orin NX – 8GB. For running this image on Jetson Nano may require some additional steps which would be added to this document once tested on Nano.
Copyright © 2025 Advantech Corporation. All rights reserved.