
Overview
LLM Langchain on NVIDIA Jetson™
About Advantech Container Catalog
Advantech Container Catalog is a comprehensive collection of ready-to-use, containerized software packages designed to accelerate the development and deployment of Edge AI applications. By offering pre-integrated solutions optimized for embedded hardware, it simplifies the challenges often faced with software and hardware compatibility, especially in GPU/NPU-accelerated environments.
Key benefits of the Container Catalog include:
| Feature / Benefit | Description |
|---|---|
| Accelerated Edge AI Development | Ready-to-use containerized solutions for fast prototyping and deployment |
| GPU/NPU Access Ready | Supports passthrough for efficient hardware acceleration |
| Model Conversion & Optimization | Built-in AI model quantization and format conversion support |
| Optimized for CV & LLM Applications | Pre-optimized containers for computer vision and large language models |
| Scalable Device Management | Supports large-scale IoT deployments via EdgeSync, Kubernetes, etc. |
Container Overview
LLM Langchain on NVIDIA Jetson™ Edge AI Container Image provides a modular, middleware-powered AI chat solution built for NVIDIA Jetson™ systems. This stack uses Ollama with Meta Llama 3.2 1B Model to serve model inference, a FastAPI-based Langchain service for middleware logic, and OpenWebUI as the user interface. It could be used to enable tool-augmented reasoning, conversational memory, custom LLM workflows and build Agents. It also offers full hardware acceleration
Key Features
| Feature | Description |
|---|---|
| Integrated OpenWebUI | Clean, user-friendly frontend for LLM chat interface |
| Meta Llama 3.2 1B Inference | Efficient on-device LLM via Ollama; minimal memory, high performance |
| Model Customization | Create or fine-tune models using ollama create |
| REST API Access | Simple local HTTP API for model interaction |
| Flexible Parameters | Adjust inference with temperature, top_k, repeat_penalty, etc. |
| Modelfile Customization | Configure model behavior with Docker-like Modelfile syntax |
| Prompt Templates | Supports formats like chatml, llama, and more |
| LangChain Integration | Multi-turn memory with ConversationChain support |
| FastAPI Middleware | Lightweight interface between OpenWebUI and LangChain |
| Offline Capability | Fully offline after container image setup; no internet required |
Container Demo
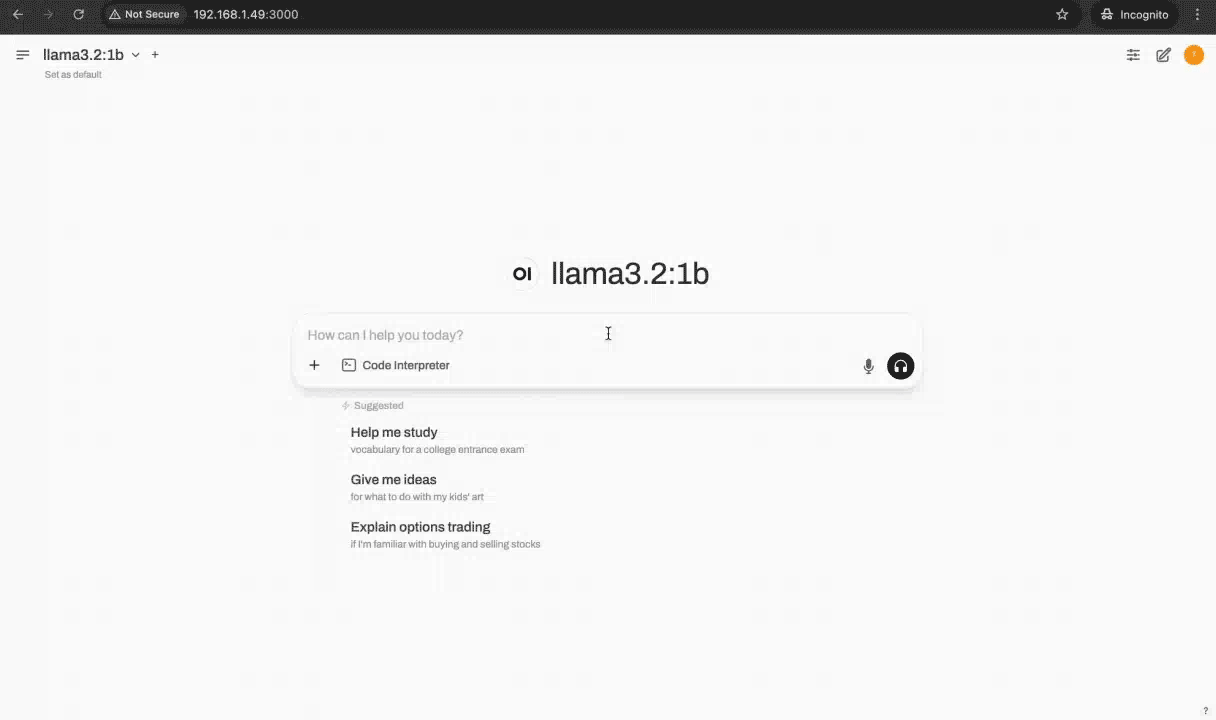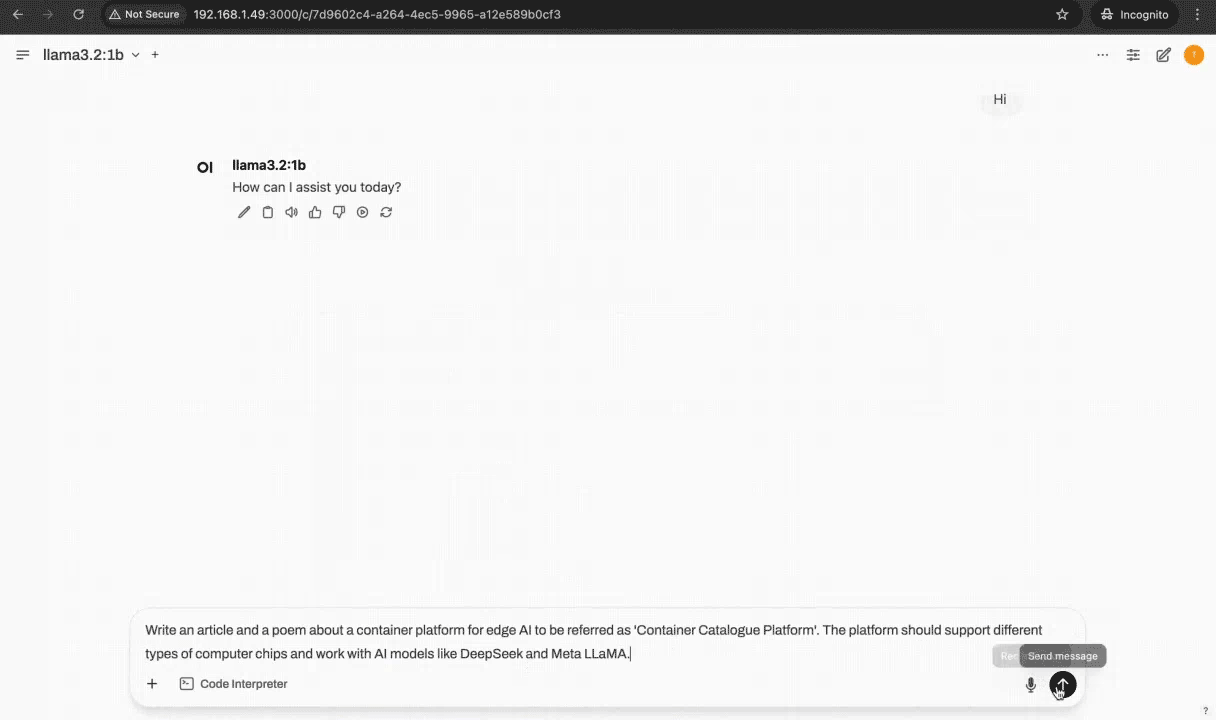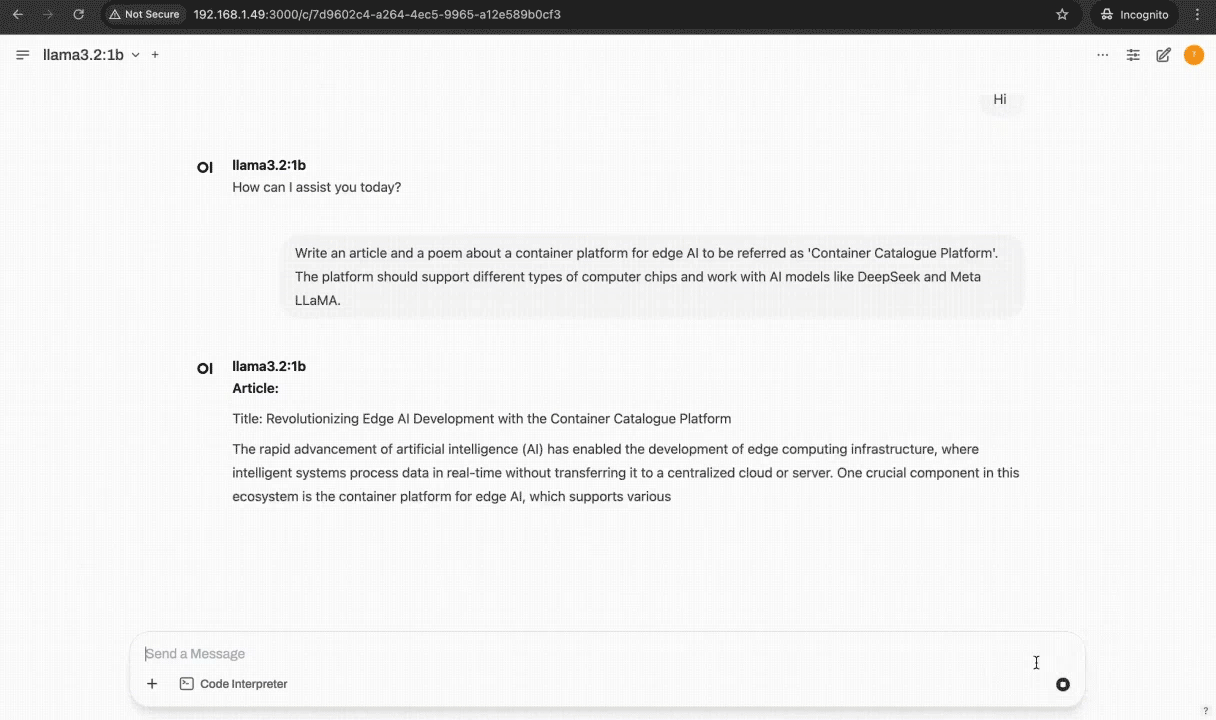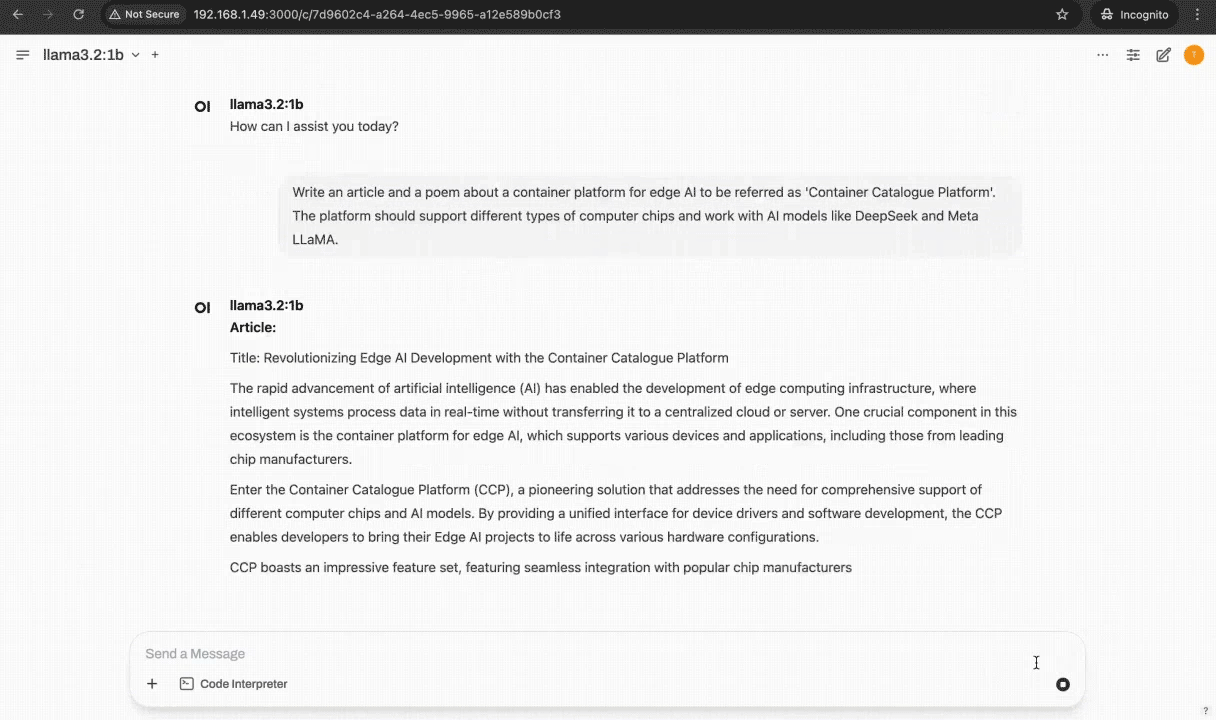
Inference Flow
User → OpenWebUI → FastAPI → LangChain → Ollama → Meta Llama 3.2 1B
Host Device Prerequisites
| Item | Specification |
|---|---|
| Compatible Hardware | Advantech devices accelerated by NVIDIA Jetson™ - refer to Compatible hardware |
| NVIDIA Jetson™ Version | 5. x |
| Host OS | Ubuntu 20.04 |
| Required Software packages | *refer to below |
| Software Installation | Jetson™ Software Package Installation |
Required Software Packages on Host Device
These packages are bound with NVIDIA Jetson™ version of the device. This container supports version 5.x.
| Component | Version | Description |
|---|---|---|
| CUDA® | 11.4.315 | GPU computing platform |
| cuDNN | 8.6.0.166 | Deep Neural Network library |
| NVIDIA® TensorRT™ | 8.5.2.2 | Inference optimizer and runtime |
| VPI | 2.2.7 or above | |
| Vulkan | 1.3.204 or above | |
| OpenCV | 4.5.4 with CUDA®: NO |
Container Environment Overview
Software Components on Container Image
The following software components are available in the base image of GPU Passthrough on NVIDIA Jetson™:
| Component | Version | Description |
|---|---|---|
| CUDA® | 11.4.315 | GPU computing platform |
| cuDNN | 8.6.0 | Deep Neural Network library |
| TensorRT | 8.5.2.2 | Inference optimizer and runtime |
| PyTorch | 2.0.0+nv23.02 | Deep learning framework |
| TensorFlow | 2.12.0+nv23.05 | Machine learning framework |
| ONNX Runtime | 1.16.3 | Cross-platform inference engine |
| OpenCV | 4.5.0 | Computer vision library with CUDA® |
| GStreamer | 1.16.2 | Multimedia framework |
The following software components/packages are provided further inside this container image & host (via build script), optimized for LLM application:
| Component | Version | Description |
|---|---|---|
| Ollama | 0.5.7 | LLM Backend, installed on Host for better performance |
| LangChain | 0.2.17 | Installed via PIP, framework to build LLM applications |
| FastAPI | 0.115.12 | Installed via PIP, develop OpenAI compatible APIs for serving LangChain |
| OpenWebUI | Latest | Provided via seprate OpenWebUI container for UI |
| Meta Llama 3.2 1B | N/A | Pulled on Host via build script |
Ollama As LLM Backend
This container leverages Ollama as the local inference engine to serve LLMs efficiently on NVIDIA Jetson™ systems. Ollama provides a lightweight and container-friendly API layer for running language models without requiring cloud-based services.
Key Highlights:
- Local model inference via Ollama API (
http://localhost:11434/v1) - Supports streaming output for chat-based UIs like OpenWebUI
- Works with quantized
.ggufmodels optimized for edge hardware - Run huggingface models by converting them to .gguf format and quantize for smaller size (refer to quantization-readme.md)
- Model behavior can be customized via Modelfile parameters (e.g., temperature, context size, repeat_penalty, etc.)
- Simple CLI (ollama run, ollama pull) for easy local model management and testing
- Supports model composition via system and user prompts for advanced prompt engineering
- Offline-first: no internet connection required after initial model pull
Model Information
This image uses Meta Llama 3.2 1B for inferencing, here are the details about the model used:
| Item | Description |
|---|---|
| Model source | Ollama Model (llama3.2:1b) |
| Model architecture | llama |
| Model quantization | Q8_0 |
| Ollama command | ollama pull llama3.2:1b |
| Number of Parameters | ~1.24 B |
| Model size | ~1.3 GB |
| Default context size (governed by Ollama in this image) | 2048 |
Hardware Specifications
| Component | Specification |
|---|---|
| Target Hardware | NVIDIA Jetson™ |
| GPU | NVIDIA Ampere architecture with 1024 CUDA® cores |
| DLA Cores | 1 (Deep Learning Accelerator) |
| Memory | 4/8/16 GB shared GPU/CPU memory |
| NVIDIA Jetson™ Version | 5.x |
Quick Start Guide
For container quick start, including docker-compose file, and more, please refer to Advantech EdgeSync Container Repository
Possible Usecases
Leverage the container image to build interesting use cases like:
| Use Case | Description |
|---|---|
| Predictive Maintenance Chatbots | Integrate with edge telemetry or logs to summarize anomalies, explain error codes, or recommend corrective actions using historical context |
| Compliance and Audit Q&A | Run offline LLMs trained on local policy or compliance data to assist with audits or generate summaries — keeping data on-prem |
| Safety Manual Conversational Agents | Deploy LLMs to provide instant answers from on-site safety manuals or procedures, reducing downtime and improving adherence |
| Technician Support Bots | Field engineers can interact with bots to troubleshoot equipment using repair logs, parts catalogs, and service manuals |
| Smart Edge Controllers | LLMs translate human intent (e.g., “reduce line 2 speed by 10%”) into control commands for industrial PLCs or middleware |
| Conversational Retrieval (RAG) | Integrate with vector databases (e.g., FAISS, ChromaDB) to retrieve context from local docs for Q&A over your custom data |
| Tool-Enabled Agents | Intelligent agents can use tools like calculators, APIs, or search — with LangChain managing the logic and LLM interface |
| Factory Incident Reporting | Ingest logs or voice input → extract incident type → summarize → trigger automated alerts or next steps |
Copyright © 2025 Advantech Corporation. All rights reserved.